

Para los que no están en contexto, spaCy es una librería de Python que provee funciones de PLN (procesamiento de lenguage natural, “NLP” en inglés) de una forma por demás fácil en comparación con, por ejemplo, NLTK.
Aunque conocía de su existencia, no había trabajado con spaCy hasta ahora que lo probé en el proyecto que tengo entre manos en el trabajo. Me era más familiar NLTK a pesar de haberlo usando en su mayoría en la versión 1 (van en la 3.5 al momento de escribir esto), pero para varias tareas spaCy es mucho más “directo”. Digamos que NLTK te da mucho poder, pero hay que ser mucho más específico al momento de manejarlo. En cambio, spaCy realiza muchas más acciones con menos interacción, lo cual puede ser bueno o extremo dependiendo del objetivo.
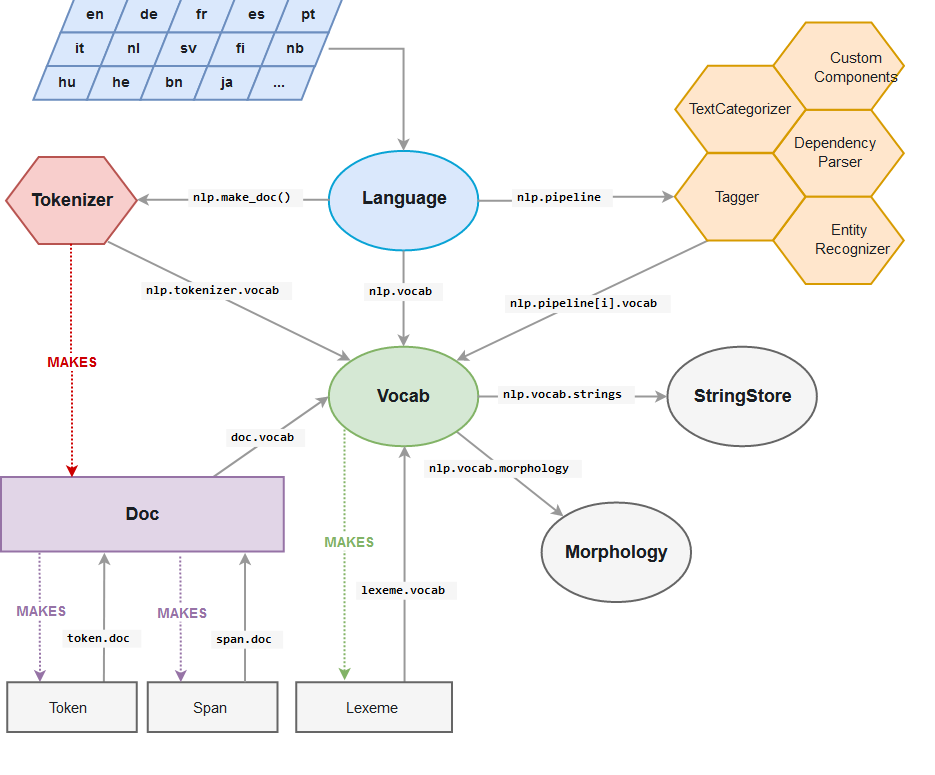 Lo interesante aquí para mí es nlp.pipeline. Una simple función, que por lo general la llaman nlp (pero uno puede definir el nombre), aplica una serie de algoritmos de análisis y reconocimiento, pero antes realiza el proceso de “tokenizar” el texto, es decir, dividirlo en entidades llamadas “tokens”, que son secuencias de caracteres agrupados en unidades semánticas. Es fácil irse con la finta de que todos los tokens son palabras, pero no es así. Existen además diferentes maneras de tokenizar, y dependiendo de la usada es el resultado que se tendrá. Por ejemplo, una de las maneras más fácil de tokenizar es agrupando caracteres en un texto separado por espacios, como este post, por ejemplo. Obviamente una tokenización así no serviría en idiomas como el japonés, donde las palabras no están separadas por espacios, pero ésa es otra historia. También es necesario destacar que separar por espacios tampoco es una forma ideal de tokenizar, incluso lenguajes como inglés, pero en sí no se puede dar una respuesta correcta sin saber cuál es el objetivo final. De eso depende la forma de crear tokens.
Lo interesante aquí para mí es nlp.pipeline. Una simple función, que por lo general la llaman nlp (pero uno puede definir el nombre), aplica una serie de algoritmos de análisis y reconocimiento, pero antes realiza el proceso de “tokenizar” el texto, es decir, dividirlo en entidades llamadas “tokens”, que son secuencias de caracteres agrupados en unidades semánticas. Es fácil irse con la finta de que todos los tokens son palabras, pero no es así. Existen además diferentes maneras de tokenizar, y dependiendo de la usada es el resultado que se tendrá. Por ejemplo, una de las maneras más fácil de tokenizar es agrupando caracteres en un texto separado por espacios, como este post, por ejemplo. Obviamente una tokenización así no serviría en idiomas como el japonés, donde las palabras no están separadas por espacios, pero ésa es otra historia. También es necesario destacar que separar por espacios tampoco es una forma ideal de tokenizar, incluso lenguajes como inglés, pero en sí no se puede dar una respuesta correcta sin saber cuál es el objetivo final. De eso depende la forma de crear tokens.
En el caso del análisis que estaba realizando (en inglés), requería manejar palabras como “well-known”, “state-of-the-art”, es decir, palabras compuestas por múltiples otras palabras, unidas por un guión (entre otros casos que no necesito nombrar), como un token. El problema es que el tokenizer de spaCy separa las palabras también por guiones, y estos a su vez forman tokens. Por ejemplo:
“well-known”
es tokenizado como
“well”, “-“, “known”
Cada elemento es un token, así que contiene más que el simple texto: su función gramatical, su forma base, entre otras cosas, todo gracias a que spaCy ejecuta las funciones de reconocimiento y análisis después de la tokenización, pero todo sucede dentro del mismo pipeline. Además, como cada token es identificado por separado, casos como el de “state-of-the-art” deben ser tratados ya que la palabra completa es un adjetivo, pero “art” por sí mismo es correctamente identificado como sustantivo. Algo se tiene que hacer.
Lo primero que se viene a la mente es la solución más sencilla: separar las palabras de ese tipo antes de pasarlos por el pipeline. Sin embargo, aunque spaCy lo ejecutará sin problemas, los resultados no son los esperados porque los modelos que se usan no han visto esa clase de tokens, lo que altera los algoritmos y produce resultados erróneos.
Cambiar el tokenizer es la siguiente opción. De hecho, NLTK provee diferentes tokenizers, pero usar NLTK significaba no usar spaCy, por lo que tareas como la lematización (regresar las palabras a su forma base) tendrían que ser procesadas y ejecutadas a mano, lo cual quería evitar por dos razones:
- Al momento de lematizar en NLTK, hay que pasar como parámetro la función gramatical de las palabras que se desea lematizar. Así, habría que primero identificar esa función, lo que en inglés se le llama POS tagging, y luego decirle a la función de lematizar que queremos, por ejemplo, lematizar los sustantivos (para, por ejemplo, poner en singular los que estén en plural), luego los verbos (para regresarlos de estar conjugados a su forma base), etc.
- La idea era usar spaCy porque hace lo anterior automáticamente, y también porque quería aprender.
Después de leer un rato al respecto me encuentro con que es posible retokenizar tokens en spaCy después de su pipeline, pero eso implica que uno manualmente tiene que indicarle el inicio y el final de los tokens y después utilizar la función spacy.tokens.doc.Doc.retokenize().merge. Todo parecía fácil, pero la literatura que encontré en ese entonces (hablamos alrededor de julio de este año) usaba spacy.tokens.doc.Doc.merge que es considerada ya obsoleta, y en otros lados manejaban las posiciones directas de los tokens y no de los spans. Así que lo mejor fue simplemente crear mi propia función
def remerge_tokens(doc: spacy.tokens.doc.Doc) -> None:
"""
Merges backs tokens after the spaCy NLP pipeline to be able to handle expressions separated into multiple
tokens as one single token.
Expressions like contractions or collocations separated by hyphens are identified as separate tokens
by the spaCy tokenizer. Example:
------------------------------------------------------------------
| Word | Tokens |
------------------------------------------------------------------
|"state-of-the-art" | "state", "-" , "of", "-", "the", "-", "art"|
|"night's" | "night", "'s" |
------------------------------------------------------------------
Note that each token contains not only the word, but also information as POS, lemma, etc., so in the case of
"state-of-the-art", the last "art" dependency is pobj (object of preposition), but the whole expression is an
adjective (https://dictionary.cambridge.org/dictionary/english/state-of-the-art), and "state" is a nmod (noun
modifier), so although the POS won't change after the remerge, the whole expression will have the attributes,
modifiers and dependencies of its first word.
In order to handle those expressions as a single token and with the appropriate token information, it is necessary
to remerge the tokens after the NLP pipeline; doing it before alters it and generally gives incorrect results.
This function identifies such expressions and remerges the tokens into one, in-place
:param doc: A spaCy document
:return: None. The remerging is done in-place
"""
i = 0
with doc.retokenize() as retokenizer:
while i < len(doc) - 1:
token = doc[i]
if not token.whitespace_:
next_token = doc[i + 1]
# If next_token is a hyphen, look-ahead for more hyphens and merge when there are no more
# This is to handle expressions like 'easy-to-assemble'
if next_token.text == "-":
index_of_last_token_after_hyphen = get_index_of_last_token_after_hyphen(doc, i + 2)
next_token = doc[index_of_last_token_after_hyphen]
attrs = {"POS": token.pos_}
span = doc[token.i:next_token.i + 1]
retokenizer.merge(span, attrs)
# Increment i so we can jump to the next correct token
i += (index_of_last_token_after_hyphen - i)
# All other cases stay as spaCy identified them
i += 1
Originalmente también estaba juntando las contracciones, pero a final de cuentas las dejé como estaban.
La función get_index_of_last_token_after_hyphen es simplemente una función recursiva que busca, como su nombre lo indica, cuál es el último token que le sigue a un guión, para poder manejar por igual palabras que tengan cualquier número de tokens pegados por guiones.
def get_index_of_last_token_after_hyphen(doc: spacy.tokens.doc.Doc, index_after_hyphen: int) -> int:
"""
Given a Document and an index, searches for the index of the word that appears after the last
hyphen in a series of tokens where words are separated by hyphens.
Example
"state-of-the-art" will be tokenized as "state", "-" , "of", "-", "the", "-", "art"
Let's suppose their indices are:
Index: 0 1 2 3 4 5 6
Tokens: "state", "-" , "of", "-", "the", "-", "art"
The first time this function is called, index_after_hyphen will be 2 because the first hyphen is
found in remerge_tokens.
Then, this function will be called recursively as long as the word in the index next to index_after_hyphen
is also a hyphen, or if there are no more tokens to check in the Document.
In this example, we check first if the index 3 (index_after_hyphen + 1) is valid and if the word in that
position is a hyphen. As it is, the function is called again with index_after_hyphen = 4 (the next index after
the hyphen we found). In this call, we check the index 5, and as it is a hyphen, the function is called again
with index_after_hyphen = 6. Now we have to check the index 7, but as it is not valid, the function will
return 6 all the way back to the stack.
:param doc: A spaCy document, obtained after running the NLP pipeline on a text
:param index_after_hyphen: The immediate next token index after a token containing a hyphen
:return: The index of the last word token after a series of tokens separated by hyphens
"""
if index_after_hyphen + 1 >= len(doc) - 1 or doc[index_after_hyphen + 1].text != '-':
return index_after_hyphen
else:
return get_index_of_last_token_after_hyphen(doc, index_after_hyphen + 2)
Aunque son funciones bastante simples, fueron esenciales para lo que estaba haciendo.